
Приветствую!
Рассмотрев ранее, как можно создавать PDF-документ, разными способами: и онлайн, и оффлайн и даже средствами Microsoft Office, пришло время рассказать, как произвести обратное действие.

Рассмотрим, как вытащить из PDF-документа текст, так чтобы можно было потом его редактировать в Word и подобных ему текстовых редакторах. То есть, попросту говоря, будем конвертировать PDF-файлы в Word.
Начнем!
Adobe Reader и аналоги
Самый простой, быстрый и бесплатный вариант:
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”
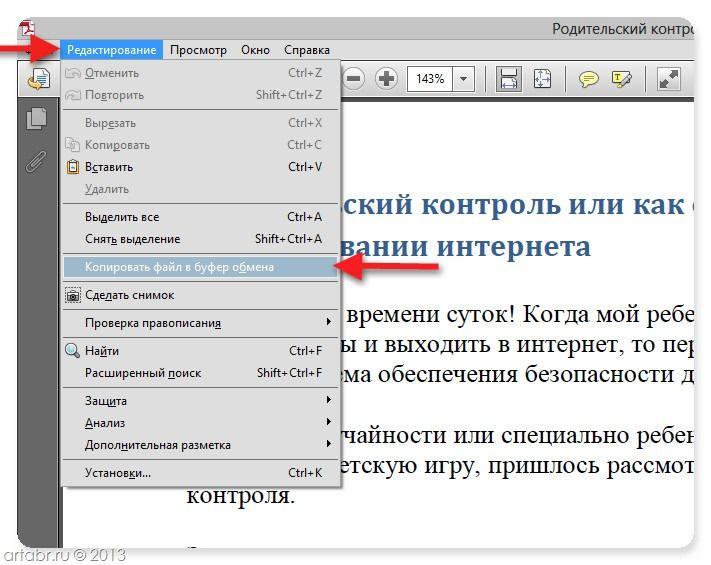
А дальше, стандартные действия: открываем Word, создаем новый документ и нажимаем кнопку Вставить или воспользуемся быстрыми клавишами (Ctrl+V).
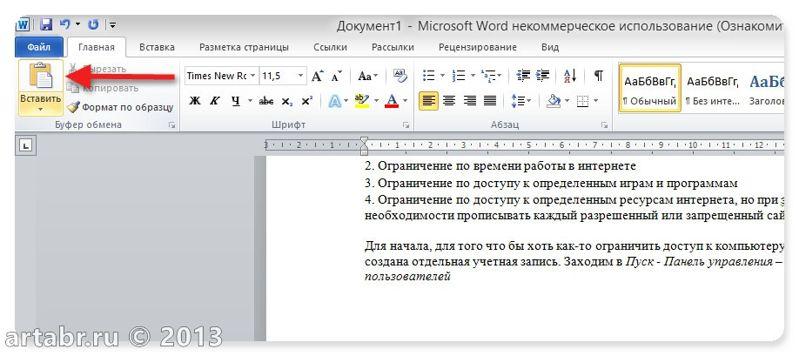
Все, можно спокойно редактировать полученный текст.
Если вам, все таки, во что бы то ни стало нужно извлечь изображение из PDF-документа, чтобы не использовать какие-нибудь программы, сделайте скриншот с экрана на котором открыт PDF-файл, из которого вы скопировали текст, но не получилось скопировать картинку.
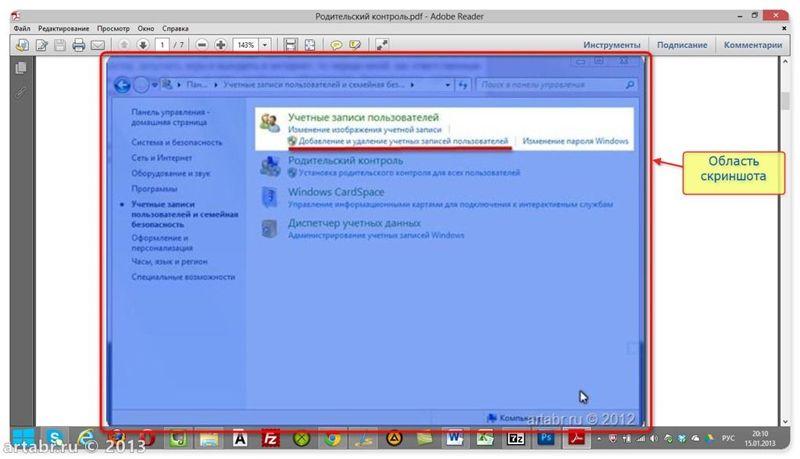
И полученное изображение вставьте в Word. Должно получиться вот так:
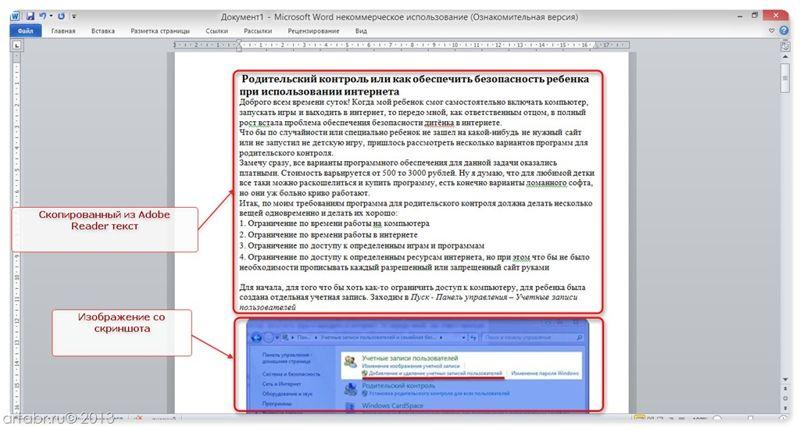
Понятно, что качество изображения будет оставлять желать лучшего, но как запасной вариант вполне подойдет.
В других просмотрщиках нужно будет сделать несколько иное действие.
Вот так в Foxit Reader (меню инструменты –> команда Выделить текст):
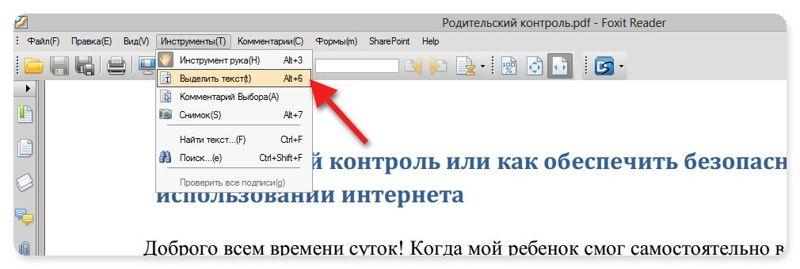
А вот так в PDF-XChange Viewer (меню Инструменты –> Основные –> Выделение):
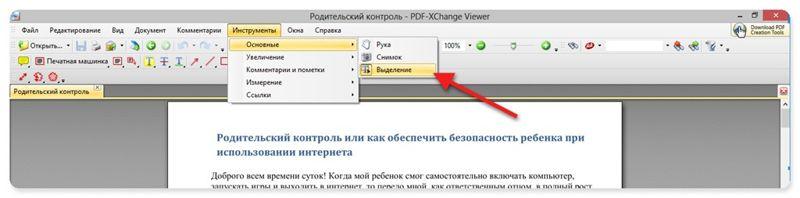
Затем выделяем нужный текст и производим стандартные действия с буфером обмена, для тех кто не догадался: Копировать (Ctrl+C) и в Word — Вставить (Ctrl+V).
Система оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток. Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А имено, с помощью специальной программы оптического распознавания текста.
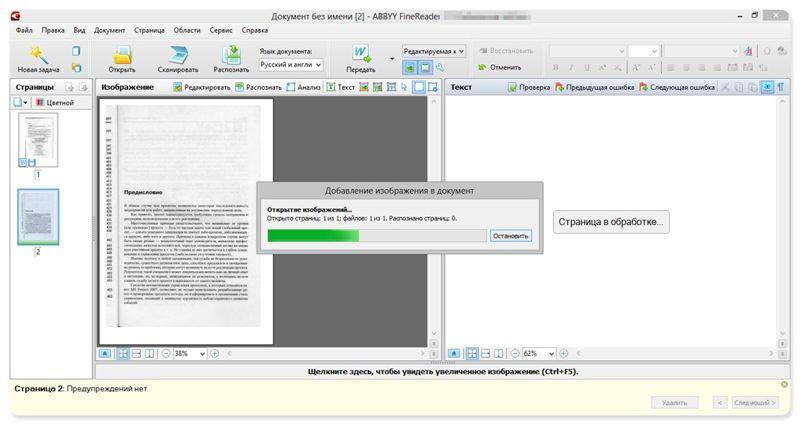
Программа называется ABBYY FineReader и, к сожалению, является платной. Но зато функционал этой программы позволит перекрыть любые требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате
Запускаем ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word
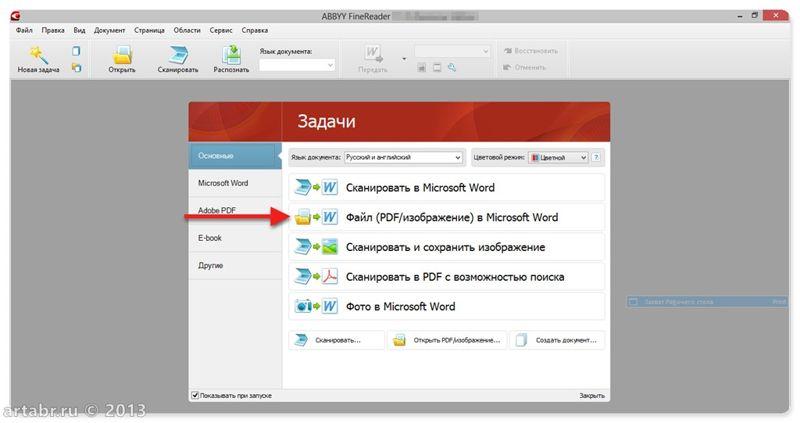
И все! Система сама распознает текст и отправляет его в Word

Онлайн-сервисы для конвертирования PDF-файлов
Вариант с онлайн-сервисами я уже описывал, единственно, что могу добавить еще пару подобных сервисов:
И опять же, ни один из онлайн-сервисов не работает с изображениями, и если текст у вас отсканирован и сохранен в формате PDF, то ничего не получится. Необходимо будет рассматривать вариант OCR.
Резюмируем
Как обычно, самым удобным оказался платный вариант, но остальные имеют право на существование, потому что не каждый день требуется преобразовывать файлы PDF. А на один раз можно или скачать демо-версию или воспользоваться онлайн-сервисом.
Если нельзя, но сильно надо, то способ всегда найдется.
Да, и еще, если Вы знаете еще какой-нибудь способ преобразования PDF-файлов, напишите мне в комментариях.
Спасибо за внимание!
Всегда ваш, Абрамович Артем!
P.S. Лирическое отступление:
Сижу расстроенная, подходит мелкий брат, суёт конфетку, я ему говорю:
— Дима, у меня взрослые проблемы, и этим их не решить.
Через 5 минут приходит с бутылкой мартини и спрашивает:
— А этим?
* * *Ребенок (2 года) в парке увидел близнецов. Долго и удивленно их разглядывал. Поворачивается к маме и с нажимом спрашивает:
— А где мой такой?!* * *
Еду в трамвае. За моей спиной сидит девочка, лет пяти. Она у окна, а рядом её мама. Девочка:
— Мам, а мам, а зачем реклама на сидениях — хочешь, скажу? Ну, вот скажи, хочешь? Ты только спроси — я тебе сразу скажу, я все тебе объясню, расскажу. Ты знаешь, зачем это? Ну, чего ты молчишь? Ну, спроси меня, давай!!!
Мама не выдерживает:
— Ну и зачем?
— Чтоб дети в трамваях читали… А не задавали взрослым глупые вопросы




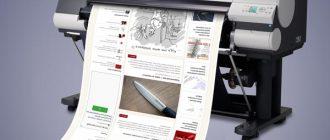

Вот такое искажение текста идет, если через буфер обмена
oaenoiaie .aaaeoi.; yeaeo.iiiay oaaeeoa; nenoaia oi.aaeaiey
aacaie aaiiuo; i.ia.aiia aiaeeca e ninoaaeaiey .anienaiee;
i.ia.aiia i.acaioaoee; a.aoe.aneee .aaaeoi.; i.ia.aiia ia-
neo.eaaiey oaen-iiaaia; naoaaia i.ia.aiiiia iaania.aiea:
yeaeo.iiiay ii.oa, eiiiu.oa.iua e oaeaeiioa.aioee e a..;
i.ia.aiiu ia.aaiaa; niaoeaeece.iaaiiua i.ia.aiiu oi.aa-
eai.aneie aayoaeuiinoe: aaaaiey aieoiaioia, eiio.iey ca en-
iieiaieai i.eeacia e a..
2 4 Eioaa.e.iaaiiue iaeao
Приветствую! В вашем случае есть масса вариантов. Это может быть и версия ридеров и офиса не подходит, и кодировка кривая или вообще файл защищен от копирования. Сложно что-то сказать-сделать когда файла перед глазами нет. Свяжитесь со мной по почте. Постараюсь помочь.
Скажите пожалуйста, я правильно понял если в документе установлен запрет на копирование, то я ничего сделать не смогу кроме как распознавать платной программой?
Да, правильно. Можно попробовать сломать, но проще распознать. Fine Reader имеет 30 дневный доступ бесплатный, думаю этого должно хватить чтобы распознать несколько файлов
Привет, Артем!
Я пару раз пробовал конвертировать pdf в word онлайн, ну, что то не чего не получилось…
Смотрю, Артем ты не как не затачиваешь статьи под поисковые запросы.
Пишешь для тех, кто уже на сайте.
Вордстатом Яндекса вообще не пользуешься?
То, что ты в keywords прописал «конвертировать pdf, pdf в word онлайн, как преобразовать pdf в word» на это же поисковики мало смотрят, если вообще смотрят. Хорошо, что в title прописал, но в тексте(я не говорю уж про заголовки) не где не встречается вообще ПРЯМОГО запроса НЕ РАЗУ!, и в description нет даже не прямого вхождения. ни в урл…
На него очень обращают внимание, после title.
Просто знаешь, вот пишешь интересно(у меня такого нет)), но не затачиваешь абсолютно… а внутренняя оптимизация, это самое главное.
Я сейчас некоторые Ларисины статьи с ходовыми запросами подгоняю по релевантности, с анализом в мегаиндексе и позиции по этим запросам значительно подрастают.
Не обижайся за …. , ну ты понял, просто такие информационные статьи должны быть в топе.
Посмотри у Александра Бобрина на сайте asbseo.ru есть бесплатный курс «Как раскрутить блог», там коротко, но понятно обо всем говориться. рекомендую.
Привет, Александр! Отвечаю по порядку:
Вордстатом пользуюсь и адворксом то же пользусь. Это раз.
Скажи, а на что тогда поисковики смотрят если не на ключевики? Как раз на дескрипшинос они мало смотрят, потому как если description не прописан, то поисковик сам подбирает снипет. А ключевики — это как раз то на что ПС смотрят в первую очередь. Это два.
То что, статья была не релевантна ключевикам — это я согласен, но я ее писал на заре своего блоговодства почти год назад, сейчас поправил немного. Это три.
Даже при всех ошибках, эта статья сидит в топ 10 Яндекса. Набери в Яше «как конвертировать pdf в word» статья будет на 6-7 месте. Правда гоша не радует, но это дело техники. Это четыре.
Ну и пять, у меня с СЕО вообще проблема — я сначала статьи пишу, а потом ключевики под них подбираю.
Вот как-то так.
PS Бобрина, Борисова и многих других читал и изучал. Но Сео — это не мое. Вот еще момент, пару месяцев назад всем известный Дмитрий Ктонановенького попал под фильтры, а знаешь почему? За переоптимизацию статей! Так что, я за человекообразные статьи, а не заточенные под ПС.
Точно, Артем, смотрю у Ларисы статьи есть с релевантностью 12-30%, а в топе…

Я наверное ерундой занимаюсь, что у всех её статей сейчас релевантность повышаю?
Тоже под фильтр бы не попасть..
Но у меня тоже редко получается 100%, обычно 70-90%. Это наверное пойдет?
Ну да, что я спрашиваю, ты же с сео не дружишь.
70-90% релевантности говорит, только о том, что наполнение статьи ключевыми словами составляет 70-90% от нормы, вот и все.
Знаешь, я у одного блогера прочитал, насчет проверки текста на тошнотность: «Проверку на тошнотность делаю на «глазок», если самого не тошнит от переизбытка ключевиков, значит и ПСам подойдет» Это я почти цитирую… Так вот, про релевантность тоже самое могу сказать, ПС становятся с каждым апдейтом все «чудесатее и чудесатее» и какой алгоритм проверки будут использовать никогда не угадаешь. Так что пиши ориентируясь на людей. Я так думаю (с)
добрый день, подскажите пожалуйста как Вы сделали такой вид статей? Или это так и было уже в готовом виде шаблона?
Добрый день! В принципе все было в шаблоне, я только немного допили. Хотел уточнить: а какой такой вид?
У меня двуязычный текст, английскую часть копирует без проблем, но русские вставки — вместо них бред латинскими буквами! Как исправить?
Пробуйте изменить шрифт, скорее всего в документе используется шрифт, который не поддерживает кириллицу.
3-способ подошел! Спасибо!
Пожалуйста! Рад был помочь…
Добрый день, Артем.
Прошу вашей помощи «разобраться» с этим pdf-файлом _http://www.viaggioadriatico.it/ViaggiADR/biblioteca_digitale/titoli/scheda_bibliografica.2006-10-26.1448905858/attachment_download/file
При копировании через буфер обмена получается нечитабельная абракадабра:
4XDQGR QHO LO ILORORJR $OEHUWR %DFFKL GHOOD
/HJDSXEEOLFzD%RORJQDSHULWLSLGL*DHWDQR5RPDJQROL
ULVW %RORJQD )RUQL O·HGL]LRQH GHO Via ggio a
Cos ta n tin opoli di Tomma so Alb er t i (16 09-162 1) VFULWWR
RGHSRULFR G·HWj EDURFFD RIIHUWR DL OHWWRUL GHOOD SUHJHYROH
FROODQDIHOVLQHD©6FHOWDGLFXULRVLWjOHWWHUDULHLQHGLWHHUDUH
GDO VHFROR ;,,, DO ;,;ª QHOOD VEULJDWLYD LQWURGX]LRQH HJOL
VHJQDODYD LO SUHPLQHQWH YDORUH VWRULFRGRFXPHQWDULR
Также существует проблема с другой частью текста — лишние пробелы. Может быть вы знаете как можно исправить ситуацию. Пример текста:
Al Nome d i Dio e d ella Bea ta Vergin e Ma r ia . Alli 18
Ma ggio a n da s s imo tu t ti in n a ve per fa r pa r ten za il giorn o
s egu en te, in p or to d elli du e ca s telli;
Добрый вечер! Думаю и не получиться. Файл сделан очень давно и кодировка не соответствует существующим форматам. Решений может быть 2: конвертировать и распознать. Второе надежнее, особенно если FineReader использовать. Даже программу покупать не придется у них есть 30-ти дневный период.
Или попробуйте сей конвертер _http://smallpdf.com/ru/pdf-to-word Я попробовал, нормальный текст получается. Придеться повозиться конечно, но никаких кракозябр и пробелов
Артем, спасибо!
Конвертер сработал.
Ну отлично. Всегда пожалуйста
Здравствуйте, Артем.
Можете помочь с этим файлом?
_http://vk.com/doc57790928_405881294?hash=bb2379894104274739&dl=b75e939911236e2a97
Никак не получается адекватного его конвертировать: или квадратики, или абракадабра.
Добрый день! Ваш документ на украинском языке. Так-то документ простой и открывается даже Вордом без проблем, но если в Ворд не установлена поддержка украинского языка — будут кракозябры. Наилучший результат получается при распозновании. Вот как-то так _https://www.dropbox.com/s/jg4umk9hg8q3i7s/%D0%94%D0%9E%D0%A0%D0%9E%D0%93%D0%98%D0%99%20%D0%94%D0%A0%D0%A3%D0%96%D0%95.docx?dl=0
Нужна срочная помощь..получила по эл.почте задание по работе,ответы и вопросы в таблице . Скопировала на рабочий стол,Начинаю распечатывать на принтере, выходит на листе (А-4) 3 столбика *как стихи*нет разлинованной таблицы,нет шапки.Хотя предварительный просмотр по принтеру таблица существует.Что я делаю ни так?На рабочем столе документ сохранился как WORD,а начинаю печатать пишет PDF.
Давайте разбираться. Пришлите мне на почту присланный вам файл, гляну
А какой программой файл открывается?
Пока я искала как и куда загрузить мои файлы для Вас,пришла подсказка на дом!У меня же в принтере отключена игла черных чернил,(печатает только цветным)а таблица идет черным…Вот бы я морочила голову….Спасибо что так быстро отозвались!
Всегда пожалуйста…
помогите пожалуйста конвектировать файл пдф не один сайт не помогает в документ верд
Добрый день! Если ни один сайт не помог, то тут только Fine Reader поможет. Уже проверено, особенно если тексты на украинском или белорусском языке
Здравствуйте, Артем! Очень нужна Ваша помощь… можно ли связаться с вами по почте? если да, то подскажите адрес
Добрый вечер! Связаться можно, все данные в контактах
Спасибо огромное Вам за отклик!))) но я уже разобралась
Всегда пожалуйста. Обращайтесь, если что
Здравствуйте ! А вот у меня вставляется как раз таки не как текст, а как картинка с растяжками в разные стороны с копированный с пдф в ворд , пдф создал из снимка на телефоне с помощью специальной программы .Подскажите как вытащить именно текст с сфотографированной страницы книги например , что бы потом ставить этот текст на страницу сайта ?
Добрый день! Тут вам только сканировать и распознавать, используйте FineReader или аналоги
Спасибо
Здравствуйте! А можно ли вытащить из pdf чертеж, для дальнейшего редактирования в программах такого рода как AutoCad, Компас и подобные?
Добрый вечер! Тут два варианта:
1. Если файл пдф создавался в этих программах, то можно. Формально это получается тот же векторный чертеж, но заархивированный в пдф.
2. Ели это скан чертежа, то нет. Это получается растровая картинка, ее только в программе типа Фотошопа редактировать
Это скан чертежа. А если его конвертировать в ABBYY FineReader в формат PDF, то получается уже не скан, и следовательно можно первым способом воспользоваться?
Нет, не получится. Файнридер только тексты распознает, все остальное он берет картинкой. Так что тут только перечерчивать.
Артем, огромное спасибо за информацию!!!!
Столько работ смогла сделать за один день, и все благодаря вашим знаниям ))
Пожалуйста! Рад, что помог)
Здравствуйте! Помогите пожалуйста! Файл ничем не защищен, но при копировании в ворд выдает следующее: Ýôôåêòèâíûì èíñòðóìåíòîì èçó÷åíèÿ ïðèðîäû èíôëÿöèîííûõ ïðîöåññîâ Áåëàðóñè. Что делать?
Сам файл — _http://bseu.by:8080/bitstream/edoc/4868/2/Kozachenko%20L.%20Ekonom.%20analiz%20inflyatsii%20v%20RB%20Vestnik%20BGEU%202_07.pdf
Добрый день! Кодировка значит не подходит. Fine Reader надо использовать для распознавания
Артем здравствуйте,можете помочь с книгой ?Нужно срочно ее из pdf в word нормально залить. Все перепробовал — ничего не получается,может у вас получится…
Добрый вечер! А finereader пробовали?
Срочно не получиться, если только завтра
Добрый день! Как скопировать из файла PDF в файл PDF необходимый участок текста?возможно?
Добрый! Вполне возможно, но тут многое зависит от исходного файла. Если исходник простой то его просто можно открыть в Word или выделить нужный кусок прямо в просмотрщике. А вот если исходник не простой, то ту надо смотреть.
Самый оптимальный вариант воспользоваться Adobe Acrobat Pro он почти со всякими умеет работать
Подскажите, пожалуйста, как распознать двуязычный табличный текст:
Левая колонка — русский, правая — французский. 11 адоб акробат про при распознавании автоматически распознает только один язык. В результате только одна колонка получается нормальной. В другой — текст с большими искажениями.
Хороший вопрос. Это может быть связано подключенными языками в самом Акробат Про, проверьте настройки или, как вариант, использовать более специальный софт для распознавания — Fine Reader например
Здравствуйте. В программе ABBYY_FineReader_14 сделала из картинки с листом книги (только текст) файл pdf. Потом из этого файла попыталась в этой же программе сделать dok. Создает документ, но он пустой. Что делать?
Добрый день! Прошу прощения за долгий ответ. Просто так доки нельзя делать, надо проводить распознование текста и тогда только можно будет в формат doc переводить
Ну вы и советы, господа, даёте…
А ничего что указанные Вами говно-сервисы попросту разбивают pdf на страницы, а потом каждую вставляют в word как картинку. Сами бы попробовали, перед тем как другим советовать.
Сами пробовали, все прекрасно рабоает. Многое от самого файла пдф зависит. Если он делан из картинки то картинкой и останется
Здравствуйте, помогите пожалуйста с нормативным документом по работе. Надо в ворд преобразовать, все перепробывал не выходит ничего( вот ссылка на файл http://my-files.ru/zsphbr
Доброго! Пардон а долгий ответ. Это у вас сканы их только распознавать, под другому ничего не выйдет
А как вытащить информацию из pdf-файла своей программой, написанной, например, на Бейсике или Паскале, ну, или скриптом каким-нибудь?
Спасибо.
ДОПОЛНИТЬ ПО СЛЕДУЮЩЕМУ ВОПРОСУ: Главного нет: какая прога нормально экспортирует текст из pdf, который был сделан из ворда. То биш в PDF уже текст есть, вот только не надо его Ctrl С + Ctrl V, а нормально быстро экспортировать.